DBOps e Apache Cassandra: vi raccontiamo un caso reale realizzato da Vista Technology
20/05/2020

Da un punto di vista prettamente DevOps, la gestione del database è un tema ancora poco affrontato se non dimenticato. Ma è indubbio che quando si parla di automazione e di orchestrazione, l’adozione di tali principi DevOps diventa fondamentale nella buona gestione del tema DB, nella semplificazione e nella spinta all’innovazione.
I temi più spinosi legati all’automation in ambito DBOps si possono riassumere come segue:
- Automatizzare l’installazione e le configurazioni di tutti i componenti
- Gestire la robustezza e resilienza del dato (backup/restore, disaster recovery, …)
- Test di integrità e consistenza a seguito dei change (per esempio di schema)
- Gestione dei secret e dei permessi
- Monitoraggio e reportistica
In questo breve use case, frutto del lavoro presso un nostro cliente in ambito Finance, ci andremo a concentrare su due aspetti di questo complesso panorama, nella fattispecie andremo a coprire il punto n. 2 e il punto n. 5
Cosa ha chiesto il cliente: automated backup, recovery e monitoring di Apache Cassandra
Nell’ambito della collaborazione con il cliente, quello che ci è stato richiesto è stato, a partire da un cluster Apache Cassandra in essere in ambiente produttivo, trovare una soluzione che andasse ad automatizzare e rendere consistenti le complesse procedure di backup e restore, in maniera da poter essere facilmente schedulabile e configurabile in termini di granularità (keyspace, table, ecc…).
Di fianco a questo strumento di automatizzazione si è inoltre reso necessario implementare un sistema di monitoraggio che andasse da un lato a tenere traccia dello stato dell’esito dello storico dei task, dall’altro tenesse sotto controllo lo stato di occupazione delle risorse dello storage esterno, utilizzato per mantenere le snapshot raccolte.
Sempre a livello di monitoraggio, il cliente ha espresso il desiderio di avere un’unica piattaforma consolidata per la raccolta e l’analisi delle metriche e dei log provenienti dall’esercizio in produzione di tutta l’infrastruttura Apache Cassandra.
La soluzione DBOps: tecnologie e integrazioni
L’architettura scelta è quella riportata in figura, composta esclusivamente da tecnologie open source:
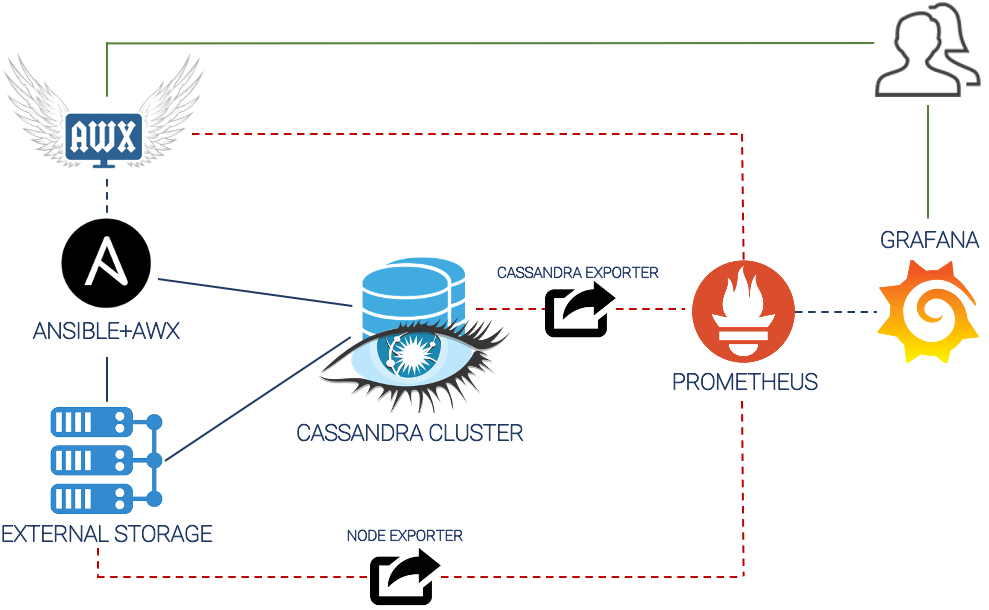
Per la parte di automazione dei task di backup/restore è stato scelto Ansible, coadiuvato per la parte grafica e UI da AWX.
Sono stati quindi sviluppati playbook ad hoc che andassero ad eseguire, in maniera distribuita e coordinata, gli opportuni comandi nativi cassandra per eseguire il backup (snapshot) ed il restore (sstableloader).
La schedulazione dei playbook di backup è stata totalmente automatizzata, andando ad usufruire del concetto di cron job, mentre per la parte di restore si è lasciato l’onere del comando all’operatore umano, che tramite la UI AWX può lanciare il playbook di restore andando a specificare anche l’opportuna granularità.
Sempre tramite task contenuti nel playbook ansible si è scelto di mantenere la persistenza delle varie snapshot temporali su uno storage esterno delle dovute dimensioni ed affidabilità.
Per monitorare l’andamento dell’esito dei playbook nel tempo, così come il monitoraggio stesso delle infrastrutture di automazione, è stata scelta un’architettura basata sull’ormai consolidato paradigma Prometheus+Grafana.
Tali strumenti ben si adattano agli eterogenei scopi della soluzione. Infatti, grazie alla funzionalità nativa di AWX di esportare metriche verso Prometheus, si è reso possibile andare a catalogare tutte quelle informazioni che riguardano la vita dei playbook (tempo di esecuzione, esito, numero di job attivi, storico, ecc…) e lo stato di salute dell’infrastruttura stessa.
Tramite l’utilizzo di un node_exporter è stato inoltre possibile andare a recuperare informazioni importanti riguardo lo storage esterno, come la disponibilità computazionale, lo stato di congestione della rete e l’occupazione del disco.
Infine, tramite l’utilizzo di un cassandra_exporter dedicato è stato possibile integrare tutte le informazioni del ciclo di vita e di esercizio del cluster Apache Cassandra, all’interno della stessa architettura di monitoraggio.
Per quel che riguarda la consultazione di tali metriche e monitoria, sono state messe a disposizione del cliente varie dashboard Grafana sviluppate ad hoc, secondo le esigenze espresse.
Sviluppi futuri
A partire dalla soluzione sviluppata, alcune evolutive messe in cantiere sono le seguenti:
- Possibilità di andare ad integrare l’infrastruttura di monitoraggio esistente per andare a soddisfare la parte relativa all’allarmistica
- Aggiunta del componente Alert Manager
- Integrazione dei canali Slack come output di notifica dei job
- Integrazione degli strumenti di ticketing (Service Now, Pager Duty, ecc…) per l’automatismo delle segnalazioni di malfunzionamenti
- Potenziamento dell’architettura di automazione per andare a soddisfare anche la parte di installazione e configurazione a seguito dell’aggiunta di nuovi nodi al cluster Cassandra.

