Strategie NetOps: possibili approcci per un’automazione Network di successo
23/11/2021

Alla fine del mese scorso siamo stati invitati a parlare durante la terza giornata della conferenza IDI2021, Incontro DevOps Italia, dedicata ai professionisti italiani del mondo DevOps (https://2021.incontrodevops.it/schedule/#Day%203). Durante quell’occasione abbiamo presentato un talk dal titolo “YANQ: Yet Another NetOps Quickstart”, dove abbiamo mostrato un possibile approccio su come affrontare al giorno d’oggi e con strumenti open innovativi, il tema dell’automazione nel mondo networking.
Il tema dell’applicazione dell’automazione e più in generale di tutti i concetti presi in prestito dal mondo DevOps, alle infrastrutture di rete è un tema molto caldo in questo periodo e innegabili sono anche gli innumerevoli benefici derivanti dalla sua adozione:
- Agilità
- Disponibilità e affidabilità
- Velocità di delivery
- Riduzione dell’errore umano
- Incremento della produttività dello staff
- Riduzione dei costi di gestione
Tuttavia, oggi le aziende si trovano ancora di fronte ad uno scoglio da superare per poter essere davvero abilitate a trasporre i principi DevOps in ambito Network e quindi poter parlare a pieno merito di NetOps:
- Infrastructure as Code (IaC)
- Singola sorgente di verità (Source of Truth, SoT)
- Pipeline di CI/CD
- Automated test
Inoltre, per essere davvero competitivi e completare il processo di transizione al NetOps, occorre non sottovalutare quello che a noi piace chiamare modello Closed-Loop Telemetry/Automation, dove i processi di CI/CD, tipici del delivery, danno seguito ad un processo di monitoraggio e continuous feedback utile come sorgente per i processi di automazione, anche in ottica di self-remediation.

L’adozione e l’applicazione dei principi cloud al mondo networking, attraverso la logica del Networking as Code, promuove anche l’adozione di architetture di rete piatte spine/leaf come elemento essenziale per ottenere i vantaggi indicati.
Il Data Center viene visto come una sorta di architettura componibile dove alla base abbiamo il POD come blocco elementare da indirizzare, auto consistente e universale nel suo uso.
Il POD usa l’architettura spine/leaf e grazie alla sua universalità è possibile applicare i principi di scalabilità orizzontale, elasticità e dinamicità nella composizione del Data Center. Attraverso la caratteristica di ripetibilità del POD entra in gioco l’automation che diventa il principio abilitante e cardine della gestione operativa indipendentemente dalle dimensioni e dalla distribuzione geografica.
Ma da cosa possiamo partire per poter applicare in toto questo paradigma? Come posso le aziende approcciarsi a questo tema in modo graduale e non-disruptive?
Innanzitutto, occorre mappare i processi con i giusti strumenti, per poi andare a mettere pezzo su pezzo in maniera progressiva:
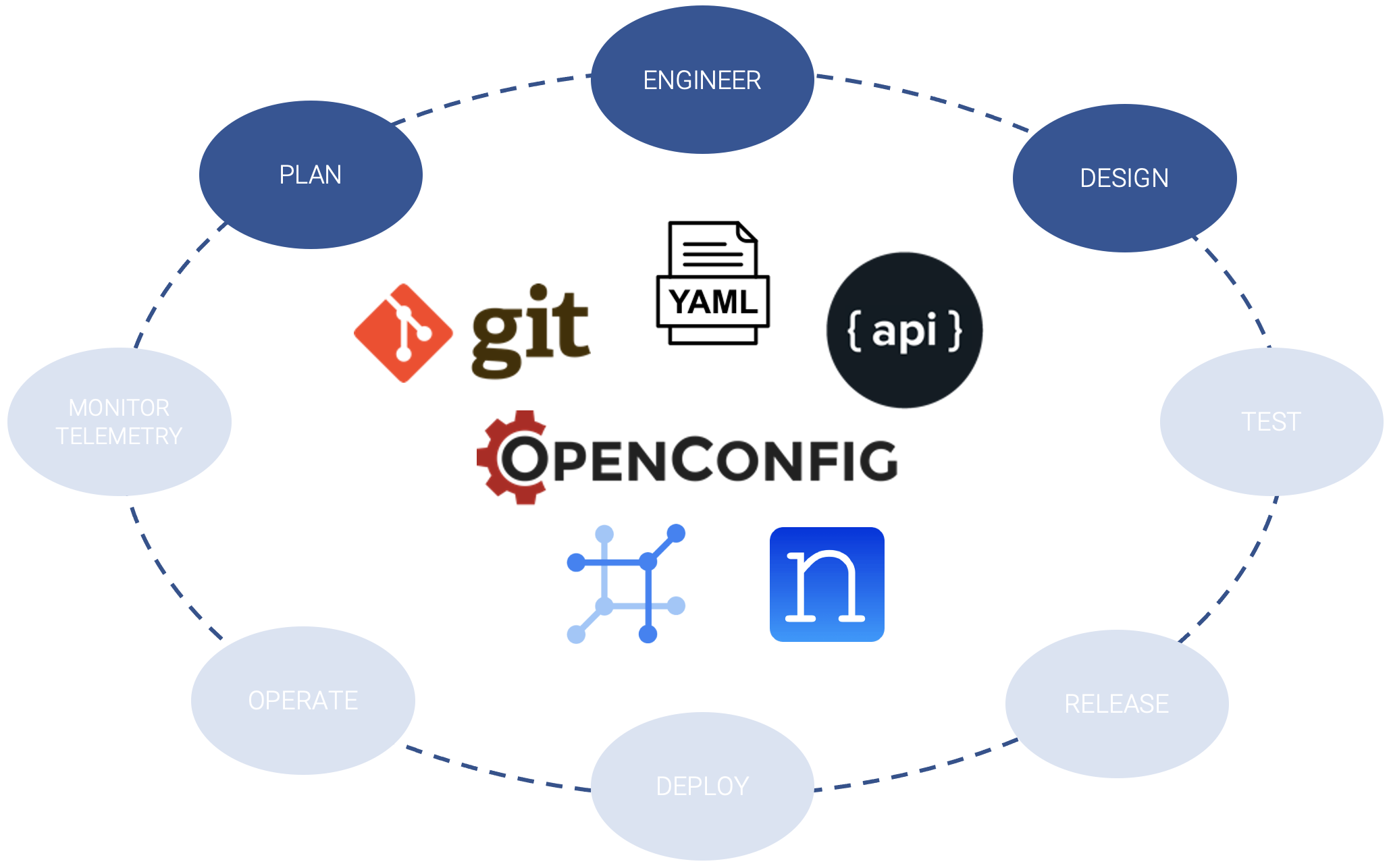
Il primo step da affrontare è quello relativo alla modalità in cui andare a trattare le sorgenti.
Abbiamo sostanzialmente due strategie possibile (utilizzabili eventualmente anche entrambe in una situazione “ibrida”):
- Approccio “sviluppo”
- Sposa una strategia IaC, in cui le risorse sono descritte (e versionate) tramite file dichiarativi, ad esempio in YAML, sposando e sfruttando al 100% tutte le caratteristiche dei processi CI/CD di sviluppo codice
- Approccio “sistemista”
- Si utilizza come SoT uno strumento di gestione, per esempio un classico IPAM evoluto, in cui l’operatore può procedere con l’inventariamento degli apparati e i dati descrittivi (es: Nautobot, NetBox, …), collegandolo poi a pipeline di automation
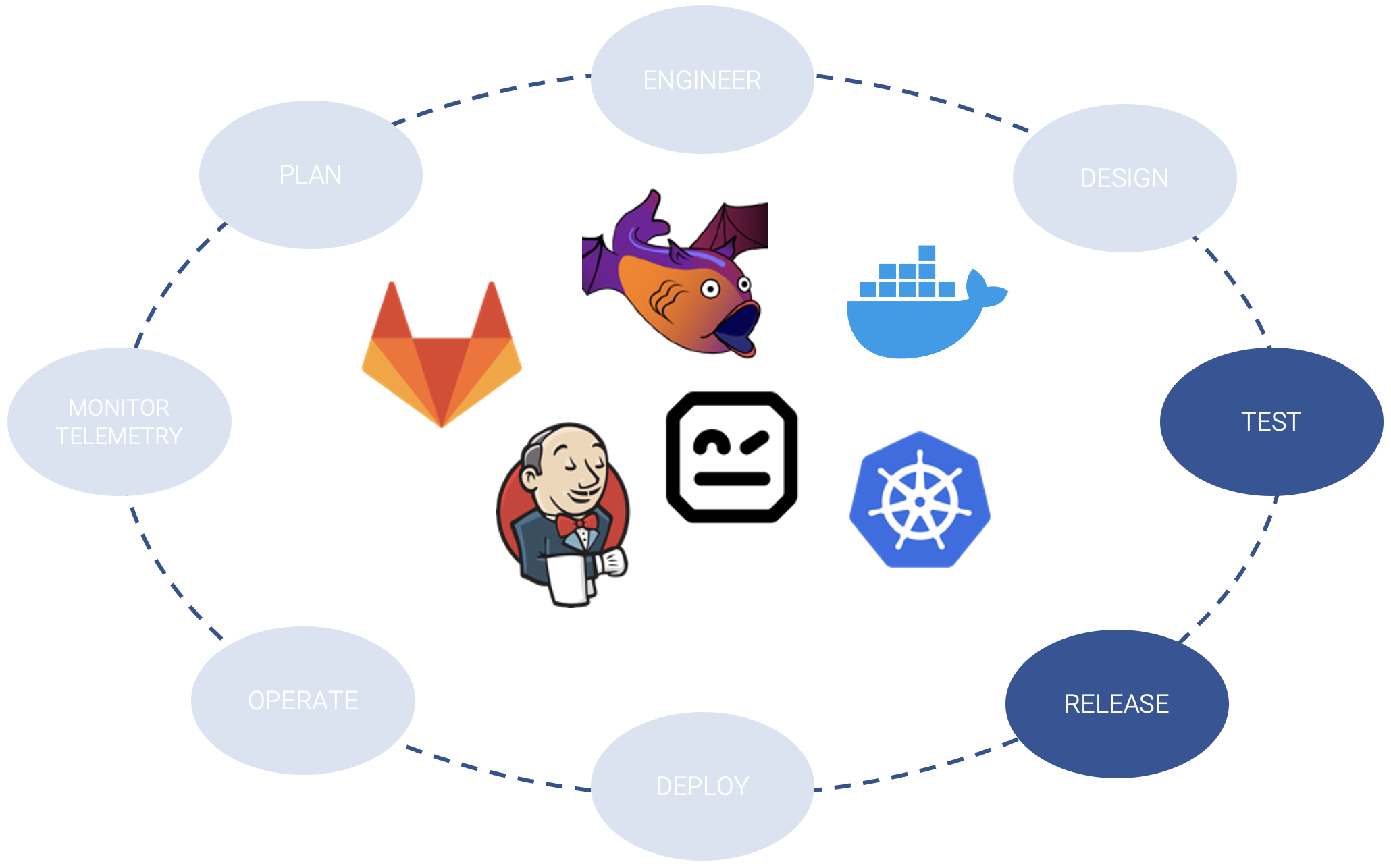
Lo step 2 è quello di andare ad integrare la sorgente con strumenti di CI/CD per operare con la fase di testing e pre-release multi-ambiente. In questa fase ci possiamo avvalere delle piattaforme tipiche sia per i processi di integration e delivery sia per gli ambienti dockerizzati, che ci consentono di riprodurre e simulare con leggerezza anche architetture complesse. In questa fase per esempio sarà possibile testare, in maniera integrata all’interno delle pipeline, le nuove topologie di rete in ambiente virtuale sicuro, avvalendosi di prodotti quali Batfish.
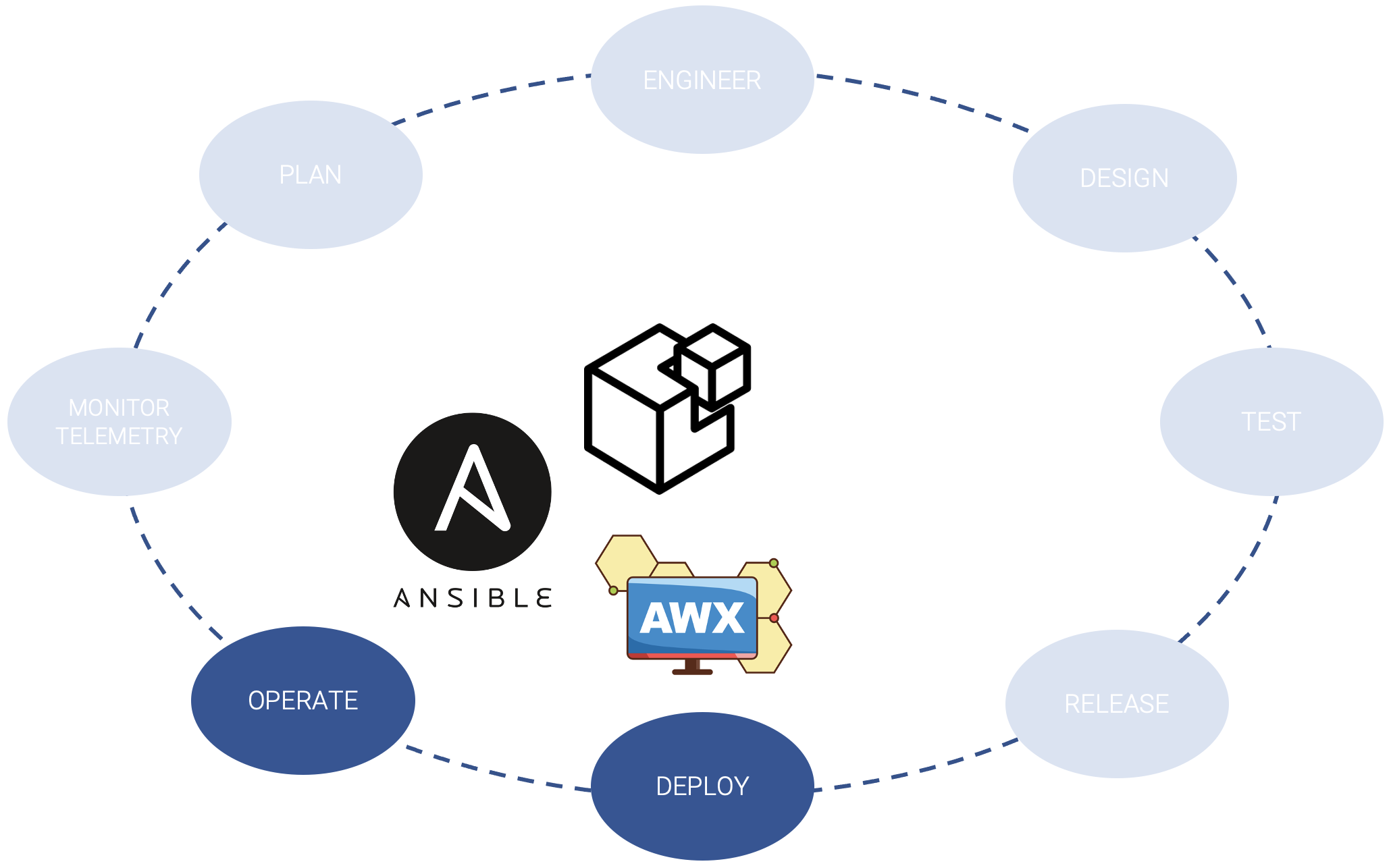
I processi di automazione sono poi il cuore dello step 3. In questa fase strumenti quali Ansible si occupano di procedere fisicamente al deploy ed alla configurazione degli apparati reali, nonché all’orchestrazione degli stati desiderati.
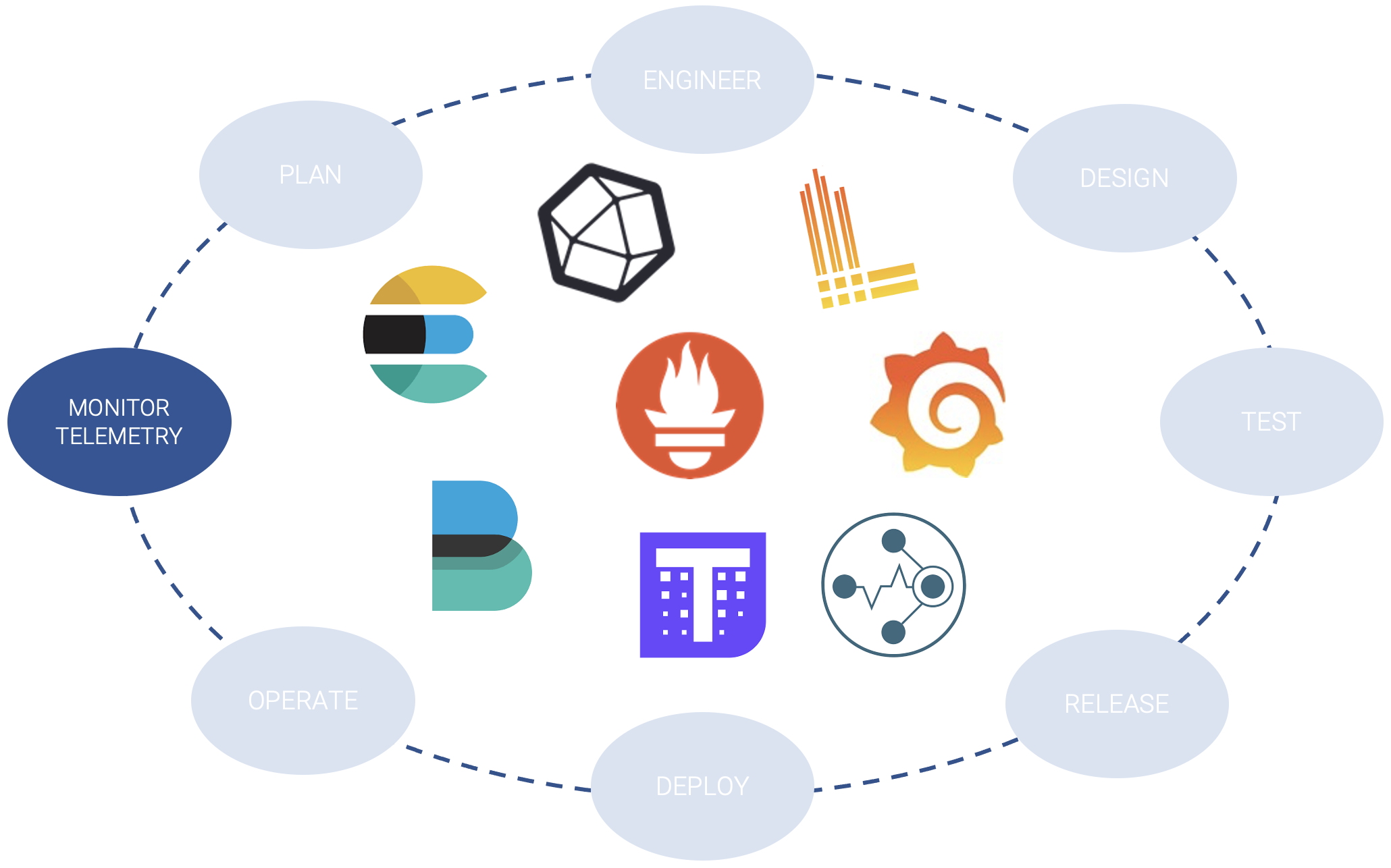
er chiudere il cerchio, in uno step 4, andremo ad integrare sistemi di telemetria, monitoraggio e log aggregation, anche questi presi in prestito dal mondo delle infrastrutture Cloud Native (es: Prometheus, Loki, Grafana, …).
Se avete la curiosità di provare questi approcci in un ambiente sandbox personalizzato vi consigliamo questi due progetti di quickstart, disponibili pubblicamente sulla nostra organization Github:
- Approccio “sistemista”: https://github.com/Vista-Technology/yanq
- Approccio “sviluppo”: https://github.com/Vista-Technology/netops-quickstart

